DSPy Is All You Need
2 weeks ago, Brett Adcock posted a public browser agent challenge; the website contained 30 steps and had to be solved in under 5 minutes. The first thing that stood out to me was that I only got to step 8 in 5 minutes, a far cry from 30 steps. Any agent that can complete this would surely have to be ‘superhuman’. In addition, no frontier model was able to solve this, so, in some sense, any solution also needs to 'push the frontier' on this particular challenge. Lastly, most of the solutions we saw were hard-coded or relied on bypasses, so a more generalizable training framework that would work on any website would be cool.
Solve this in under 5 minutes and I’ll offer you \$500k/year in cash plus several million in equity
— Brett Adcock (@adcock_brett) February 2, 2026
I'm building a Computer-Use team, goal is to use computers better than humans
No experience or PhD needed
Instructions:
1. Solve all 30 challenges on this website in under 5… pic.twitter.com/CEZLhMR8mY
High-level Overview
We used DSPy for recursive prompt improvement: automate the loop of "run the bot, see where it fails, have an LLM rewrite the instructions, repeat." The agent starts with a blank system prompt and a browser, runs the challenge, and produces a full transcript of every tool call, result, and error. The optimization step itself uses three LLMs in a loop
- Optimizer that identifies what can be improved
- Reflection model that acts as an LLM-as-a-judge to verify whether each proposed change is actually good (this inner loop runs around 50 times to pick the best candidate — normally DSPy would run ~460 but we found diminishing returns beyond about 25 iterations).
- Editor that actually rewrites the prompt.
A curriculum controller ratchets up the difficulty (starting at just 3 steps and advancing by 3 each time the agent clears the target) so the prompt evolves incrementally from easy to hard. To speed up training we also assume system prompt is generalizable across different models, if we start training from scratch with a weaker model (GPT OSS 120b) it would waste compute just to get the basics right, so we start from the frontier (Opus 4.6) then go down in intelligence to Haiku 4.5 then OSS 120B. This way we can train most policies in under 2 hours. Because the system learns its own strategies from scratch rather than being hardcoded, you could point it at any variation of this challenge or a completely different website and it would figure it out given a few hours to train.
Harness Overview
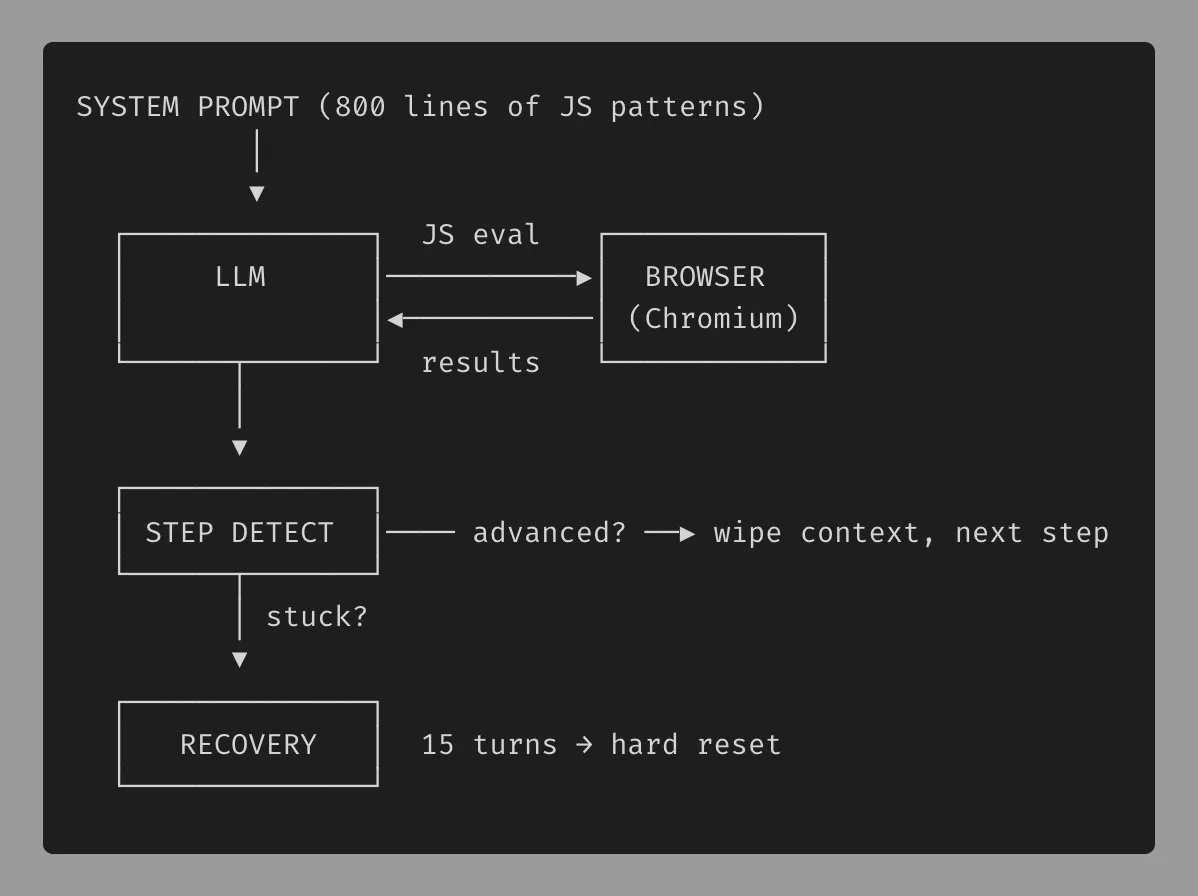 The agent harness gives the LLM a Playwright-controlled Chromium browser exposed through just two tools
The agent harness gives the LLM a Playwright-controlled Chromium browser exposed through just two tools
- browser_navigate to go to a URL
- browser_evaluate to execute arbitrary JavaScript on the page
The main loop sends the system prompt and conversation history to the model via OpenRouter, executes whatever tool calls come back, detects step advancement, and wipes the conversation after each step to keep token usage low. Results from every tool call are truncated to 4K characters and the whole run produces a transcript JSON and metrics JSON that feed into the optimizer for the next training iteration.
Note: On step 19 we utilize a sessionStorage bypass because there is no place to input the solution to get the code. On step 30, we utilize the same bypass. After retrieving the code and click validate it always says incorrect (presumable unsolvable).
Results
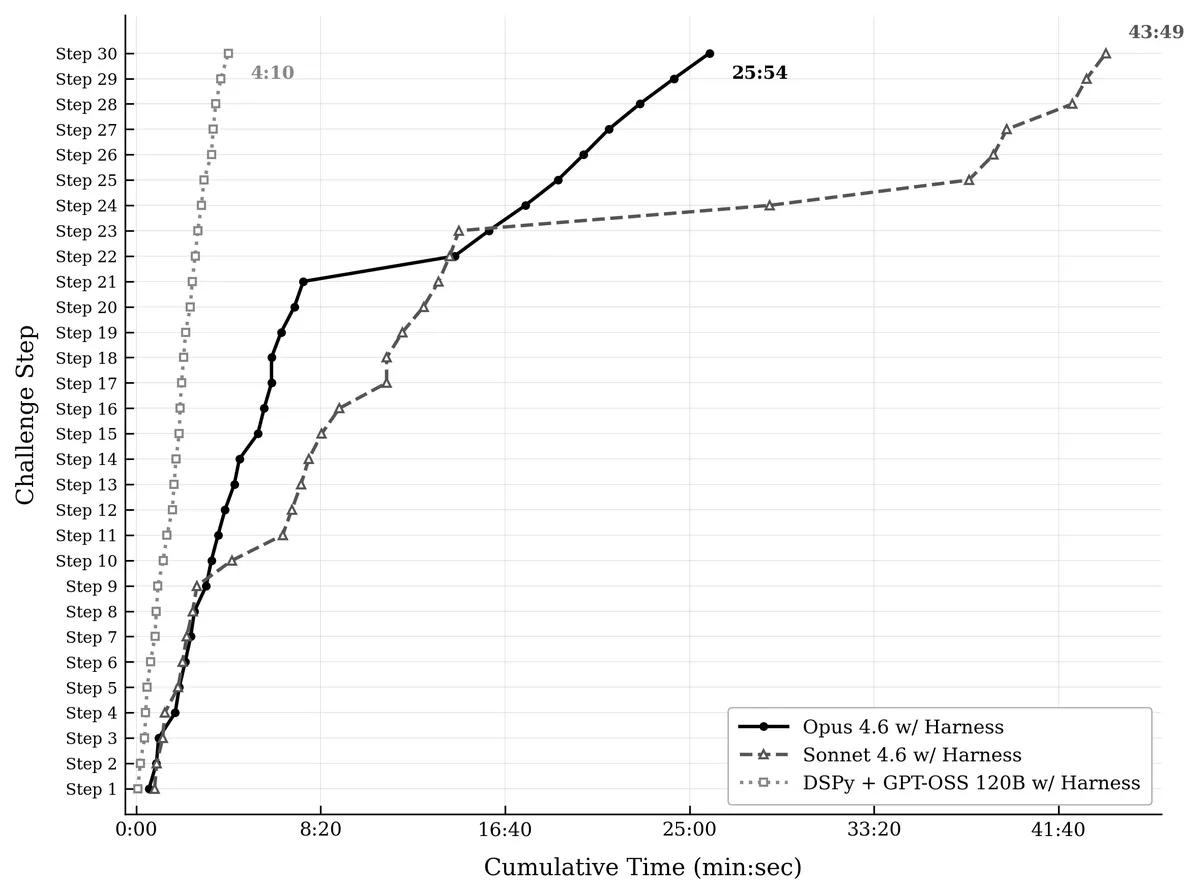
After post training we can see a significant latency and performance improvement using GPT-OSS 120B. An interesting observation happened when Opus 4.6 was stuck on step 22, after 7 minutes it decided to reverse engineer the XOR encryption and retrieving the code that way which it proceeded to reuse every step from there on. Sonnet 4.6 did not try to bypass resulting in a significant slow down.
We also benchmarked Haiku 4.5 and GPT-OSS 120B base with the same harness. Haiku 4.5 self terminated at step 3 and GPT-OSS 120B did not make it past step 1.
Full Run Video
Code Repo
Terminal Log
=== Run Summary ===
- steps completed: 30/30
- total time: 265.6s
- agent time: 265.6s
- api calls: 99
- tool calls: 95
- tokens: 1,430,418 in / 36,319 out
- cost: $0.0627
The core mechanism here is surprisingly simple from first principles: you have a prompt that defines agent behavior, a score function that measures performance, and an LLM that can rewrite the prompt to improve the score. This creates a hill-climbing loop where the prompt is the parameter being optimized, the evaluation is the gradient signal, and the LLM acts as the optimizer, no fine-tuning required (thus viable for frontier closed models).
This is the same fundamental insight driving a wave of self-improving systems across domains. Poetiq demonstrated this on ARC-AGI, where they hill-climb benchmark performance by having an LLM iteratively rewrite its own reasoning strategies: run the puzzle set, identify which puzzles failed, generate candidate prompt revisions that address those failure modes, evaluate the revisions, and keep the best one. Each iteration improves the score, and because the search happens in natural language rather than weight space, the discovered strategies are interpretable and transferable (we see this anecdotally as the prompts that improve opus 4.6 performance on the Adcock benchmark also generalized to GPT-OSS 120B).
The same loop applies to code generation, data analysis, customer support, or as we showed here, browser automation. Anywhere you have a repeatable task with a measurable outcome, you can point this optimization loop at it and let the system discover its own best practices.
One other step we could have taken would be to allow another agent to edit the reward function as well. This would make this methodology generalizable to all repeatable workflows on the web, even ones that don't necessarily move linearly in ‘steps,’ but alas, our 12 hours were up.
Some thoughts:
- If all you needed to achieve superhuman performance on individual webpages, shouldn’t there be a service that uses dspy to find the optimal way of navigating each website, almost a new index of the web for AI to use the browser efficiently?
P.S. if your company is interested in post training internal models email me at eric@clado.ai